Introduction图像压缩属于图片处理的一种,经过处理后的图片,文件体积一般会变小。
图像压缩分为无损压缩和有损压缩,无损压缩对质量没有影响,压缩率比较低;而有损压缩则通过牺牲一定的质量,达到更高的压缩率。一般压缩比越高,体积越小,质量越差。
因此在评测质量的时候,分为客观评测和主观评测。其中客观评测是指用一些算法来对图像打分,而主观评测则是人眼对图像质量进行打分。毫无疑问,主观质量评测费时费力,而且不同人评测的结果不一样,包含了很多噪声。同时,主观评测无法给出精度很高的分数,只能给出一个粗略的分数;而客观质量与主观质量相反,精准度高,容易计算,但客观质量指标的缺点是他和主观不一定吻合,目前也没有完美的客观指标;
图片的内容千奇百遍,不同场景下的内容特征会差异很大。因此在评测的时候需要根据自己的需要选择出代表图片来,使用这些图片来做评测;
图像压缩通常情况下会涉及比较复杂的操作,一般都比较费时,在比较的时候需要考虑到耗时这个因素;因此在评判一个压缩算法,除了需要考虑质量和体积,还需要考虑耗时。
Test-set
在评测的时候,需要先选定测试集,可以使用公开的测试集,也可以使用自己定制的测试集。以下是几个测试集可供选择
Cloudinary CID22
JPEG AIC-3
Kodak & CLIC
客观评测
针对图片的客观指标是一个很活跃的研究领域,每年都会有新的客观指标出来。常用的客观指标有PSNR, SSIM, VMAF.SSIM, DSSIM, ssimara 2, VMAF。
PSNR
PSNR是pixel-level的指标,它会对比两张图片中每个像素的差异并加权平均。PSNR没有考虑人眼视觉模型,和主观不能很好的吻合,但计算简单。
后面基于PSNR开发了HVS-PSNR,WPSNR和XPSNR,其中WPSNR在计算的时候对每个块赋值一个权重,最终的PSNR是一个加权的PSNR.
SSIM
SSIM是2004年提出的,它同时考虑了均值,对比度和结构信息,比PSNR更符合人眼的主观。SSIM的具体公式如下:
$SSIM(x, y) = \frac{(2\mux\mu_y + C1)(2\sigma{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)}$
基于SSIM也有很多变体,包括MS-SSIM,DSSIM等
SSIM考虑到了人眼视觉效应,对平坦区域的失真更加敏感,这和人的主观是吻合的。
VMAF
VMAF是由Netflix提出来的,内部计算了多个指标,如Visual Quality Fidelity(VIF), Detail Loss Measure(DLM) 以及Temporal Information(TI),最终采用机器学习(SVM)的方式对多个指标进行融合得到最终的分数。VMAF与主观相关性较高,在业界内被广泛使用。
VMAF相关的模型有VMAF-Neg(VMAF-Non-enahncement-gain),
主观评测
主观评测主要由人员做主观打分,并对打分后做统计分析,目前主流的评测方法都是基于ITU-R BT.500来做的.
一般使用Double Stimulus Continuous Quality Scale的方式进行评测,评测的时候把原图和测试图并排放置,并随机打乱顺序,由观看者对两幅图片进行打分,分值是5分制,分别表示Excellent, Good, Fair, Poor and Bad. 因此这是一种全参考的设置方式。
还有种常见的主观评测是GSB(Good:Same:Bad)评价,适合于两个编码器对比分析;
除此以外,还可以采用以下几种方式:
ACR(Absolute Category Rating): 每次评估一个视频,对视频打分; 量级分为(Bad, Poor, Faire, Good, Excellent)
DCR(Differential Comparison Rating): 每次评估一对视频(源视频,处理后视频),对处理后视频相对于源视频的差异进行打分;(Imperceptible, Perceptible but not annoying, Slightly annoying, Annoying, very annoying)
PC/CCR: 每次评估一对视频(都是处理后的视频,对比两者的处理效果),给出哪个视频更好的打分;打分的量级分为(Much worse, worse, slightly worse, the same, slightly better, Better, Much Better)
打分之后一般使用MOS(Mean Opinion Score)或者DMOS(Differential Mean Opinion Score)来统计出分数来;MOS常用与ACR,分数越高,质量越好;而DMOS常用于DCR,分数越低,代表与原视频越接近).
打完分之后需要做统计分析(ANOVA, T-Test),判断下观察到的差异是因为质量变化还是因为随机的改变;另外可以检查和客观指标的吻合度,同时分析对于不同的subgroup的表现如何。
速度对比
可以计算编码/解码所用时间,内存占用率等来判断下编码器的速度;
不同Codec的对比
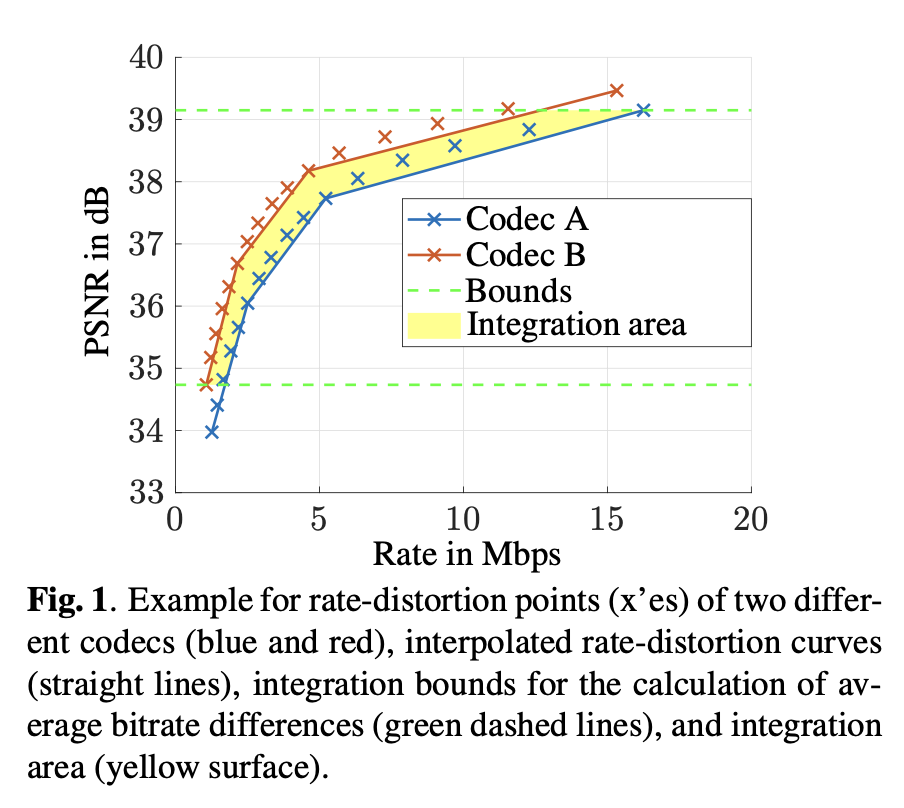
因为编码器在不同质量等级下生成图片的质量和大小都不一样,如果只跑出一个数据来,因为质量和体积都不一样,无法直接比较。工业界常用的方式是使用多个质量等级编码出多个数据(≥ 4),然后计算出对应的质量和体积,最后计算BD-Rate。例如有两个JPEG编码器A和B,其中A是anchor编码器,B是测试编码器。计算BD-Rate的时候,可以用A和B跑出四个质量等级的码流,分别计算码流对应的码率和质量,最后计算BD-Rate,如果BD-Rate为正值,如3%,可以解释为要达到同样的客观指标,B要比A多用3%的码率,也就是B的压缩率更低。如果BD-Rate为负值,如-10%,则说明B要比A少用10的码率,即B的压缩率更低。
注意计算BD-Rate的时候,需要考虑到选用的客观指标和质量等级,这些需要和实际场景中的匹配上。BD-Rate的介绍可以参考How to use BD-Rate to evaluate codecs。
评测框架可以参考WebM codec-compare
总结
图片压缩的评测并不简单,中间有很多的坑,在实践中需要选好测试集,并交叉对比主观评测的结果和客观评测的结果,作为一个参考。在涉及多个codec的时候,可以采用BD-Rate来比较两个Codec。
]]>
{kind=link}